


랜덤분기 확률이 이상해서 질문 드립니다.

우선 랜덤분기를 다음과 같이 만들어봤습니다.
분기는 총 7개이기 때문에
랜덤분기를 판단,[random. 6]으로 만들었습니다.

그 후, 각 분기별로 카운트를 두어 그 분기가 선택될 때마다 카운트 +1이 되도록 하였습니다.
그리고 카운트 뒤에는
연산으로
[변수, 0]*100/([변수, 0]+[변수, 1]+[변수, 2]+[변수, 3]+[변수, 4]+[변수, 5]+[변수, 6]+[변수, 7])
과 같이 하여 각 분기별 선택 확률을 연산하였습니다.

저는 이렇게 하면 각 분기별 선택 확률이 거의 동일하게 100/7인 약14.2%정도 나올 줄 알았습니다.
그런데,
랜덤분기를 계속 반복해보니 결과가 이상합니다.

위와 같이 각 확률이 서로 다를뿐만 아니라 7번 변수는 한번도 선택되지 않았습니다.
혹시 맨 위에서 제가 짠 루틴이 문제가 있는 것일까요?
선배님들께 조언을 구합니다.

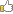 0
0 -0
-0
그룹계산시 항목이름으로 우선 검색합니다.
위는 순수 숫자로 항목이름을 지정한 경우로....
랜덤값 0인 경우 -- 항목이름 "0" 이 없으므로 당연히 0번항목으로 인식됩니다.
그러나 랜덤값 1~6의 경우 -- 항목이름 "1"~"6"으로 먼저 인식되어
위와 같은 현상이 생깁니다.
0번 항목의 경우 2배 확률로 표기된 이유이기도 합니다.(0번항목과 항목이름 "1"이 동일 항목)