


안녕하세요. 이제 한번 정도 강좌를 쓰면 마지막이군요. 앞서 아나콘다와 파이썬, 텐서플로우 및 CUDA, cuDNN까지 설치를 마쳤습니다. 오늘은 이미지를 학습 시켜볼텐데요. 사실 오늘 해보는 내용이 가장 중요합니다. 어떤 학습 모델을 이용할지부터 이미지의 전처리를 어떻게 할지가 정확도에 많은 영향을 주기 때문입니다. 아무튼, 처음부터 학습하기 위한 코딩을 하거나 그렇지는 않습니다. 구글에서 공개한 Inception V3를 이용해서 다시 학습시키는 쉬운 방법이 있거든요^^; 학습 알고리즘과 아키텍처는 Inception V3에서 제공하는걸 재사용합니다. 아래는 구글이 공개한 아키텍쳐예요.

아참~ 이전에 모두 Visual Studio Code를 설치하셨죠? Visual Studio Code를 실행하고 아래와 같이 아나콘다 폴더를 시작 폴더로 설정하세요. 학습을 위해서 여러가지를 준비해야 하지만~~~ 뭐 이런식이다라는 정도만 알아도 될거 같네요.

아무래도 Visual Studio Code에서 파이썬 코드를 작성하고 프로젝트를 관리하는게 편리하죠^^; 메뉴의 파일에서 폴더를 선택하고 아나콘다 폴더를 선택하면 자동으로 위 그림처럼 로딩이 됩니다. 이제 학습에 사용할 샘플 이미지들을 만들어야 합니다. 저는 아래와 같이 만들었는데요. 사실... 이미지가 몇장 없어서 복사 붙여넣기로 대충 넣었습니다. 아마도... 이것 때문에 나중에 모델의 퀄리티가 상당히 낮을걸로 예상됩니다. 여러분들은 제대로된 이미지로 테스트 해보시기 바랍니다. 아니면... 이미지 협찬을~!!! ^^;

이미지 폴더를 만들때 규칙이 있습니다. 앞에서도 몇번 설명했지만, 경로에 띄어쓰기나 대문자가 포함되지 않도록 하는게 중요합니다. 물론, 한글도 사용하지 마세요^^; 그래서 아래 그림처럼 내문서나 사용자 아이디가 들어갈 수 있는곳을 피해서 폴더를 만들고 이미지들을 넣어줬습니다. 가능하면 C 또는 D드라이브의 루트에 이미지를 넣어놓는게 좋을겁니다. 그리고, arrows폴더 안에 bottom, left, top, right폴더가 있습니다. 이 폴더 이름이 분류 이름이 됩니다. 만약, 분류할 이미지가 flower, car, fly, man, woman... 이런식이라면 폴더 이름도 이렇게 지어주면 됩니다.

각각의 폴더에는 이미지들을 넣어주면 됩니다. 이 때 이미지 이름도 폴더 이름과 동일하게 숫자와 영문 소문자로 이름을 지어주세요. 특수문자나 한글이 들어가면 여러가지 문제를 발생 시키거든요^^; 이런 사소한것 때문에 많은 시간을 소비하는 것은 좋지 않습니다. 가급적이면~ 규칙에 맞게 파일들을 정리하는게 좋습니다.

이제 구글에서 inceptionv3_retrain.py파일을 다운로드 받습니다. 파일 소스는 깃헙에 올라와 있는데요. 아래 주소에서 받으시면 됩니다.
링크는 강퇴 당하므로 다운로드는 알아서..ㅋㅋ
그리고, Visual Studio Code의 tools폴더에 넣어주세요.

이제 학습시켜볼까요? Visual Studio Code의 터미널에서 아래 명령을 실행시킵니다.
python inceptionv3_retrain.py --image_dir C:\arrows

사실 소스에서 몇가지 수정을 해야 하지만~ 디테일한 부분은 나중에 알아보기로 할께요. 이미지 포멧이나 이미지 사이즈를 학습시키는 이미지에 맞게 변경해야 정확도가 올라갑니다. 물론, 이미지를 흑백으로 하거나 특징이 잘 나타날 수 있도록 해주는것도 중요합니다. 관련 포럼에 보면 이미지 사이즈는 클수록 좋다고 하는군요. 이런 부분들은 테스트를 해봐야 어떤 결과물이 좋은지 판단할 수 있을거 같아요. 참고로~ 그래픽카드가 좋을수록 정확도와 속도가 올라갑니다. 학습이 완료되었군요^^

아래 폴더에 가보면 새로운 파일들이 생성되어 있을겁니다. 테스트하느라 불필요한 파일들도 보이는데요. 중요한건 output_graph.pb와 output_labels.txt입니다.

output_labels.txt를 열어보면 폴더 이름이 레이블로 되어 있는것을 알 수 있습니다. 머신러닝 모델은 output_graph.pb 파일인데요. 용량이 약 85메가정도 됩니다. 이미지가 많을수록 용량은 커지게 됩니다. 대략 200장정도 학습시킨 결과인데요. 같은 이미지를 다 복사붙여넣기해서 사실 불필요한 데이타가 많이 포함되어 있을거에요. 당연히 정확도도 떨어지겠죠^^;

아래 그림은 텐서보드로 학습된 결과를 시각화해서 보여주는건데요. 이걸 이용해서 어떤 데이타를 넣어서 결과를 받아볼지 분석해야 합니다. 그리 어려운 작업은 아니라서 누구나 쉽게 할 수 있긴합니다.

이렇게해서 이미지를 학습하는 방법에 대해 알아봤습니다. 구글에서 이미지를 추론할 수 있는 아키텍처를 공개해서 내가 원하는 이미지를 쉽게 학습시킬 수 있게 되었습니다. 그리고, 이 모델을 엔지엠 매크로에서 사용할 수 있습니다. 학습이 어떻게 진행되었는지... 그리고, 인풋 데이타와 아웃풋 데이타를 어떻게 가져와서 처리해야 하는지는 다음 시간에 알아보도록 하겠습니다~ 엔지엠 매크로는 구글이나 네이버에 검색하면 공식 사이트가 바로 나와요. 텐서플로우보다 더 쉽게 딥러닝을 할 수 있는 욜로 딥 러닝도 포함되어 있어서 오딘이나 리니지2m과 같은 3d 게임에서 몹도 인식이 잘 됩니다. 물론 오토룬도 100프로 풀리구요.
참고로~ 티처블머신을 검색해보면... 쉽게 학습시켜서 사용할 수 있는 구글 사이트도 있습니다~ 이 사이트에서 상하좌우 이미지를 약 100장씩 넣고 테스트를 해봤는데... 정확도가 90프로 이상이더라구요. 참고로 학습 모델을 다운로드 받을수도 있어요.

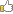 0
0 -0
-0



ㄷㄷㄷ 이젠 매크로를 위해 머신러닝을 해야 합니다 대단하십니다